


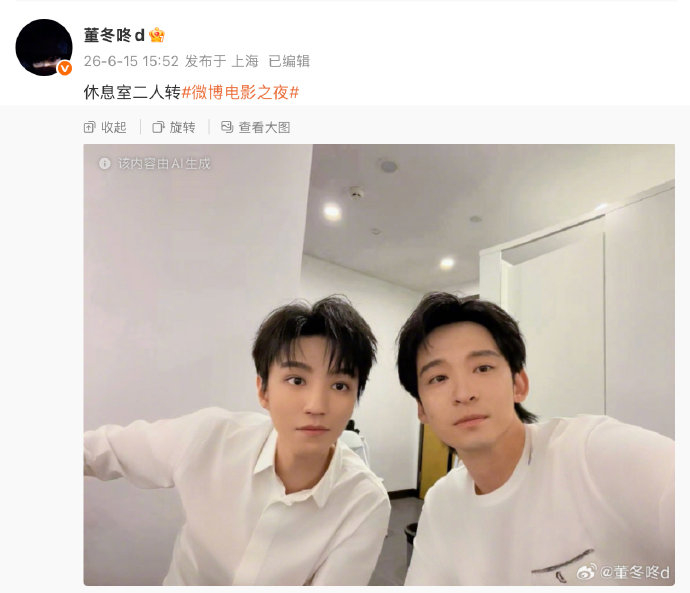
董子健与王俊凯合照被标注“该内容由AI生成”,根本原因是微博平台的内容识别算法出现误判,将一张真实拍摄的合影错误归类为AI合成图片,而照片中两人过于完美的皮肤质感与光影效果则加剧了系统的“误杀”。
一、事件核心事实
1. 发布背景- 2026年6月15日,董子健(微博账号“董冬咚d”)在微博电影之夜后台发布与王俊凯的合照,配文“休息室二人转”。- 照片中两人身穿白衬衫,面对镜头微笑,画面自然温馨。- 该照片左下角赫然显示灰色提示条:“该内容由AI生成”。
2. 平台标注机制- 微博平台自2025年起逐步推行AI生成内容强制标注政策,系统会自动检测图片特征并打上标识。- 此次标注并非由发布者手动添加,而是平台算法在审核时自动触发的判定结果。
二、网友反应与二次传播
1. 娱乐话题迅速发酵- 事件在微博引发多个关联话题,包括#董子健王俊凯合照被判ai生成了#、#王俊凯董子健自拍像AI#等。- 大量网友在评论区调侃:“帅得不像真人”“长得很帅像AI”。- 有网友注意到刘昊然“缺席”合照,留言“怎么不叫上刘源(刘昊然原名)”。
2. 媒体跟进报道- 新浪电影、钱江视频等媒体账号均对此事件进行了报道,强调“最搞笑的是左上角显示‘该内容由AI生成’”。- 部分自媒体账号将其与AI幻觉话题关联,借势讨论算法误判的普遍性。

三、误判的直接原因分析
1. 照片本身“过于完美”- 微博电影之夜现场专业灯光下,两人皮肤状态极佳,几乎无瑕疵,类似AI生成的“磨皮效果”。- 有网友直接评价:“生图颜值自带贵气”“帅成AI了”。- 这种高度理想化的画面特征容易触发AI图像检测模型的“阈值警报”。
2. 算法模型的局限性- 当前AI内容识别模型主要依赖像素级特征(如边缘平滑度、光影一致性、纹理重复模式等)。- 专业摄影棚光使得照片中面部高光与阴影过渡极其均匀,符合AI生成的典型特征。- 系统在缺乏上下文语义理解(如这是明星后台花絮)的情况下,会优先输出“疑似AI生成”的结论。
3. 平台标注策略的“宁错勿漏”- 为应对深度伪造内容泛滥,各大平台普遍采用偏严格的检测标准。- 在“误标记真图”与“漏标假图”之间,算法倾向于前者,以避免用户被虚假信息误导。- 此次事件正是这种保守策略的典型案例——真实照片因“长得太像AI”而被系统反向误判。
四、关联背景:AI幻觉在社交平台的扩散
1. 同类误判并非孤例- 同一时间段,豆包AI助手曾因“模型幻觉”将电话号码错误标记为养殖场电话,还将历史人物黎元洪照片混淆为演员范伟。- 这些案例共同指向当前AI识别技术“过度拟合”或“特征误匹配”的普遍问题。
2. 公众对AI标注的认知落差- 多数用户对AI生成内容标识的准确率抱有过高期待,认为系统“不会出错”。- 当真实照片被误判时,反而形成了“反讽”式的传播效果——网友戏称“帅到连AI都以为是假图”。
五、事件后续与影响
1. 董子健未删除该条微博- 截至2026年6月15日晚,董子健未对AI标注进行回应或删除,照片仍保留在其微博首页。- 该互动也唤起了粉丝对三人此前综艺《恰好是少年》的回忆,多次提到“希望能重开这档综艺”。
2. 对平台算法优化提出警示- 此次事件再次提示:AI识别系统需引入更多上下文线索(如发布会现场时间戳、发布者身份、照片元数据)来降低误判率。- 单纯依赖图像底层特征的检测模型,在面对高质量真人摄影时仍存在明显短板。
3. 社交娱乐属性大于技术争议- 从传播效果看,绝大多数网友将此事视为“有趣的意外”,而非深究算法缺陷。- 话题热度集中在“帅气”与“搞笑”层面,使一次技术乌龙转化为明星的正面曝光。
六、总结性归纳
直接原因:微博AI图像识别算法因照片光影均匀、皮肤细腻等特征,错误触发“疑似AI生成”标签。
底层矛盾:专业摄影设备+顶级明星颜值共同创造的“完美画面”,恰好与AI生成图像的特征向量高度重合。
社会意义:事件折射出AI时代“真与假”界限的模糊,以及技术检测工具在绝对化判断上的局限性。
